
9.1 正则介绍
正则是学习shell脚本之前必学的内容。如果这部分内容学的越好,那么shell脚本编写能力就会越强。
在计算机科学中,正则表达式是这样解释的:它是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。在很多文本编辑器或其他工具里,正则表达式通常被用来检索和/或替换那些符合某个模式的文本内容。许多程序设计语言都支持利用正则表达式进行字符串操作。对于系统管理员来讲,正则表达式贯穿在我们的日常运维工作中,无论是查找某个文档,抑或查询某个日志文件分析其内容,都会用到正则表达式。
其实正则表达式,只是一种思想,一种表示方法。只要我们使用的工具支持表示这种思想那么这个工具就可以处理正则表达式的字符串。常用的工具有grep, sed, awk 等。这3种工具都是针对文本的行才操作的。

9.2 9.3 grep / egrep

语法: grep [-cinvABC] 'word' filename
-c :打印符合要求的行数
-i :忽略大小写
-n :在输出符合要求的行的同时连同行号一起输出
-v :打印不符合要求的行
-A :后跟一个数字(有无空格都可以),例如 –A3则表示打印符合要求的行以及下面两行
-B :后跟一个数字,例如 –B2 则表示打印符合要求的行以及上面两行
-C :后跟一个数字,例如 –C2 则表示打印符合要求的行以及上下各两行
把包含 ‘halt’ 的行以及这行下面的两行都打印出,如下所示:

把包含 ‘halt’ 的行以及这行上面的两行都打印出,如下所示:

把包含 ‘halt’ 的行以及这行上面和下面的各两行都打印出,如下所示:
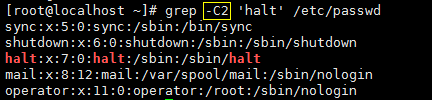
举几个典型例子如下所示:
- 过滤出带有某个关键词的行并输出行号
![]()
- 过滤不带有某个关键词的行,并输出行号
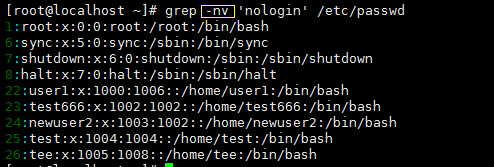
- 过滤出所有包含数字的行

- 过滤出所有不包含数字的行

- 把所有以 ‘#’ 开头的行去除
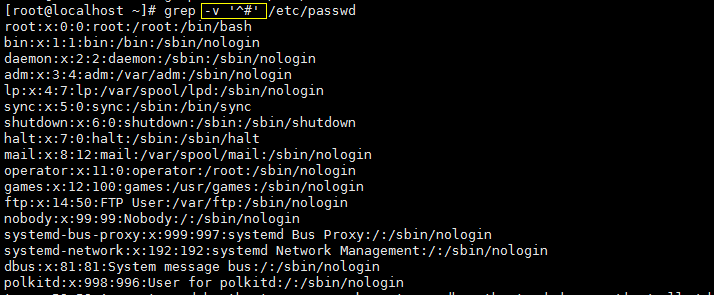
- 去除所有空行和以 ‘#’ 开头的行

在正则表达式中, “^” 表示行的开始, “$” 表示行的结尾,那么空行则可以用 “^$” 表示。
- 过滤任意一个字符与重复字符

. 表示任意一个字符,上例中,就是把符合r与o之间有两个任意字符的行过滤出来, * 表示零个或多个前面的字符。
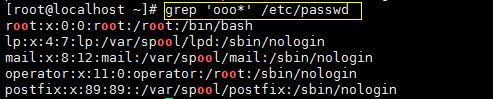
‘ .* ’ 表示零个或多个任意字符,空行也包含在内。
- 指定要过滤字符出现的次数
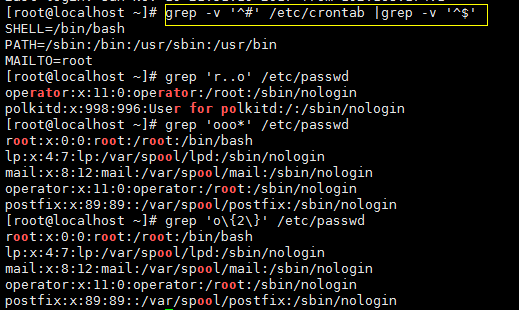
这里用到了{ },其内部为数字,表示前面的字符要重复的次数。上例中表示包含有两个o 即 ‘oo’ 的行。注意,{ }左右都需要加上脱意字符 ‘\’, 另外,使用{ }我们还可以表示一个范围的,具体格式是 ‘{n1,n2}’ 其中n1<n2,表示重复n1到n2次前面的字符,n2还可以为空,则表示大于等于n1次。
上面部分学习的grep,egrep这个工具也比较常用,简单点讲,后者是前者的扩展版本,我们可以用egrep完成grep不能完成的工作,当然了grep能完成的egrep完全可以完成。如果嫌麻烦,egrep了解一下即可,因为grep的功能已经足够可以胜任您的日常工作了。下面学习一下egrep不用于grep的几个用法。
- 筛选一个或一个以上前面的字符
egrep 'o+' test.txt
和grep 不同的是,egrep这里是使用’+’的。 - 筛选零个或一个前面的字符
egrep 'o?' test.txt
- 筛选字符串1或者字符串2
egrep 'aaa|111|ooo' test.txt
- egrep中( )的应用
egrep 'r(oo)|(at)o' test.txt
用( )表示一个整体,例如(oo)+就表示1个 ‘oo’ 或者多个 ‘oo’egrep '(oo)+' test.txt